
 Octopus
OctopusRead Preprocessing
The basic idea of read pre-processing is to remove or modify reads containing artifact sequences that are likely to mislead variant calling or increase runtime by introducing spurious candidates.
Deduplication#
Read duplicates can arise during sequencing in several ways, and are library-prep and technology dependent:
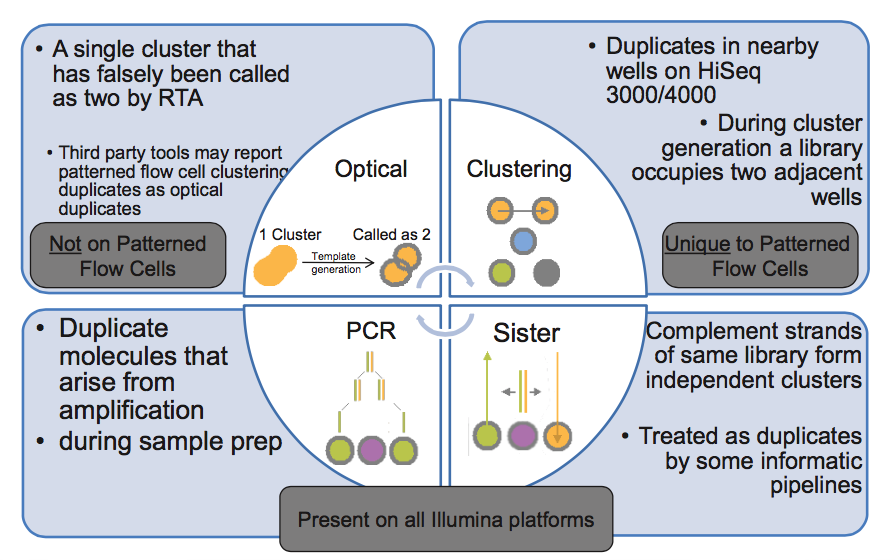
See here and here for more detailed discussions on how duplicates arise.
Duplicates can be problematic for variant calling as they can introduce systematic error (e.g. copying errors during PCR). Removing them is usually recommended for WGS libraries, but this remains somewhat controversial.